Run folktexts benchmark with a different data source
This notebook describes how to use the folktexts pipeline to run a benchmark on a different tabular dataset (distinct from the ACS tasks provided out-of-the-box).
In this example, we have mapped 11 columns of the Medical Expenditure Panel Survey (MEPS) dataset (survey panels 19, 20, and 21).
Data codebook available at this link.
[1]:
from pathlib import Path
import numpy as np
import pandas as pd
import folktexts
print(f"{folktexts.__version__=}")
folktexts.__version__='0.6.0'
Define mappings for each dataset column using ColumnToText: each value of each column should be mapped to a meaningful text representation.
[2]:
from folktexts.col_to_text import ColumnToText
# AGE
meps_age_col = ColumnToText(
"AGE",
short_description="age",
value_map=lambda x: f"{int(x)} years old",
)
# REGION: Census region
meps_region_col = ColumnToText(
"REGION",
short_description="US region",
value_map={
1: "Northeast",
2: "Midwest",
3: "South",
4: "West",
},
)
# SEX
meps_sex_col = ColumnToText(
"SEX",
short_description="sex",
value_map={
1: "Male",
2: "Female",
},
)
# MARRY / MARRY31X
meps_marital_status = ColumnToText(
"MARRY",
short_description="marital status",
value_map={
1: "Married",
2: "Widowed",
3: "Divorced",
4: "Separated",
5: "Never married",
6: "Inapplicable - Under 16 years old",
7: "Married during current survey round",
8: "Widowed during current survey round",
9: "Divorced during current survey round",
10: "Separated during current survey round",
},
)
# HONRDC: Honorably discharged from military
meps_education_col = ColumnToText(
"HONRDC",
short_description="honorably discharged status",
value_map={
1: "Yes, honorably discharged from military",
2: "Not part of military or not honorably discharged",
3: "Inapplicable - Under 16 years old",
4: "Inapplicable - Now on active duty",
},
)
# RTHLTH / RTHLTH31: Perceived health status
meps_health_status_col = ColumnToText(
"RTHLTH",
short_description="self-rated health status",
value_map={
1: "Excellent",
2: "Very good",
3: "Good",
4: "Fair",
5: "Poor",
-1: "Inapplicable - Missing data",
-7: "Inapplicable - Refused to answer",
-8: "Inapplicable - Don't know",
},
)
# MNHLTH / MNHLTH31: Perceived mental health status
meps_mental_health_status_col = ColumnToText(
"MNHLTH",
short_description="self-rated mental health status",
value_map={
1: "Excellent",
2: "Very good",
3: "Good",
4: "Fair",
5: "Poor",
-1: "Inapplicable - Missing data",
-7: "Inapplicable - Refused to answer",
-8: "Inapplicable - Don't know",
},
)
# POVCAT / POVCAT15: Poverty category
meps_poverty_category_col = ColumnToText(
"POVCAT",
short_description="poverty category",
value_map={
1: "Poor",
2: "Near poor",
3: "Low income",
4: "Middle income",
5: "High income",
},
)
# INSCOV / INSCOV15: Insurance coverage
meps_insurance_coverage_col = ColumnToText(
"INSCOV",
short_description="insurance coverage",
value_map={
1: "Private insurance",
2: "Public insurance",
3: "Uninsured",
},
)
# DIABDX: Diabetes diagnosis
meps_diabetes_col = ColumnToText(
"DIABDX",
short_description="diabetes diagnosis",
value_map={
1: "Yes, diagnosed with diabetes",
2: "No, not diagnosed with diabetes",
-1: "Inapplicable - Under 17 years old",
},
missing_value_fill="Inapplicable - Under 17 years old",
)
# HIBPDX: High blood pressure diagnosis
meps_high_blood_pressure_col = ColumnToText(
"HIBPDX",
short_description="high blood pressure diagnosis",
value_map={
1: "Yes, diagnosed with high blood pressure",
2: "No, not diagnosed with high blood pressure",
-1: "Inapplicable - Under 17 years old",
},
missing_value_fill="Inapplicable - Under 17 years old",
)
Define the target column mapping and the question to prompt the LLM with by instantiating a MultipleChoiceQA object:
[3]:
from folktexts.qa_interface import MultipleChoiceQA, Choice
TARGET_COL = "UTILIZATION"
utilization_qa = MultipleChoiceQA(
column=TARGET_COL,
text="What was this person's estimated number of doctor visits in the past year?",
choices=(
Choice("More than 10 doctor visits (high health-care utilization)", 1),
Choice("10 or fewer doctor visits (low health-care utilization)", 0),
),
)
# UTILIZATION: Number of doctor visits
meps_utilization_col = ColumnToText(
TARGET_COL,
short_description="doctor visits",
question=utilization_qa,
)
Optionally, you can define a numeric question prompt that asks for a verbalized probability by instantiating a DirectNumericQA object:
[4]:
from folktexts.qa_interface import DirectNumericQA
utilization_numeric_qa = DirectNumericQA(
column=TARGET_COL,
text=(
"What is the probability that this person has high health-care utilization? "
"(i.e., more than 10 doctor visits per year)"
),
)
Define the prediction task be instantiating a TaskMetadata object:
[5]:
# Helper dict to access ColumnToText objects by column name
meps_columns_map: dict[str, object] = {
col_mapper.name: col_mapper
for col_mapper in globals().values()
if isinstance(col_mapper, ColumnToText)
}
[6]:
from folktexts.task import TaskMetadata
meps_task = TaskMetadata(
name="health-care utilization",
description=(
"predict whether an individual had low or high healthcare utilization "
"in the past year by their number of doctor visits"
),
features=[col.name for col in meps_columns_map.values() if col.name != TARGET_COL],
target=TARGET_COL,
cols_to_text=meps_columns_map,
sensitive_attribute="SEX",
multiple_choice_qa=utilization_qa,
direct_numeric_qa=utilization_numeric_qa,
)
Set whether to use numeric risk prompting or the default multiple-choice Q&A prompting:
[7]:
meps_task.use_numeric_qa = False
# meps_task.use_numeric_qa = True
Load MEPS data and instantiate the Dataset object:
[8]:
from folktexts.dataset import Dataset
DATA_PATH = Path(folktexts.__file__).parent.parent / "notebooks" / "data" / "meps.csv"
meps_df = pd.read_csv(DATA_PATH)
dataset = Dataset(
data=meps_df,
task=meps_task,
test_size=0.4,
val_size=0,
subsampling=0.1, # NOTE: Optional, for faster but noisier results!
)
Optionally, you can subsample the data to get faster but noisier results, with:
dataset.subsample(0.1) # Keeps only 10% of the data
Load huggingface LLM:
Note: Update MODEL_NAME_OR_PATH as needed.
[9]:
# Canonical HF id (gated): "meta-llama/Meta-Llama-3-8B-Instruct"
# Use the *instruction-tuned* model: it follows the multiple-choice answer
# format far better than the base model, yielding usable risk scores.
MODEL_NAME_OR_PATH = "/fast/groups/sf/huggingface-models/meta-llama--Meta-Llama-3-8B-Instruct"
[10]:
from folktexts.classifier import TransformersLLMClassifier
from folktexts.llm_utils import load_model_tokenizer
model, tokenizer = load_model_tokenizer(MODEL_NAME_OR_PATH)
llm_clf = TransformersLLMClassifier(
model=model,
tokenizer=tokenizer,
task=meps_task,
batch_size=20,
context_size=800,
)
Example LLM prompt for this task:
[11]:
X_sample, _y_sample = dataset.sample_n_train_examples(n=1)
print(llm_clf.encode_row(X_sample.iloc[0], question=llm_clf.task.question))
predict whether an individual had low or high healthcare utilization in the past year by their number of doctor visits
Information:
- The age is: 37 years old.
- The US region is: West.
- The sex is: Female.
- The marital status is: Never married.
- The honorably discharged status is: Not part of military or not honorably discharged.
- The self-rated health status is: Good.
- The self-rated mental health status is: Good.
- The poverty category is: Poor.
- The insurance coverage is: Private insurance.
- The diabetes diagnosis is: No, not diagnosed with diabetes.
- The high blood pressure diagnosis is: No, not diagnosed with high blood pressure.
Question: What was this person's estimated number of doctor visits in the past year?
A. More than 10 doctor visits (high health-care utilization).
B. 10 or fewer doctor visits (low health-care utilization).
Answer:
Run benchmark on MEPS data
[12]:
from folktexts.benchmark import BenchmarkConfig, Benchmark
bench = Benchmark(llm_clf=llm_clf, dataset=dataset)
A note on class imbalance
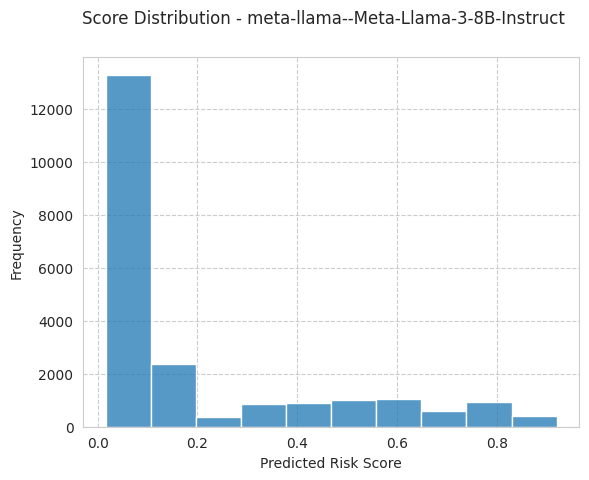
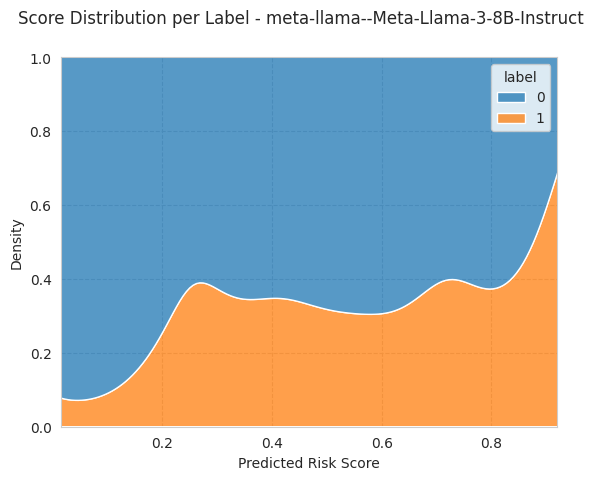
The UTILIZATION target is ~17% positive (the canonical AIF360 cut-off of ≥10 total visits), so two choices matter here:
Use an instruction-tuned model.
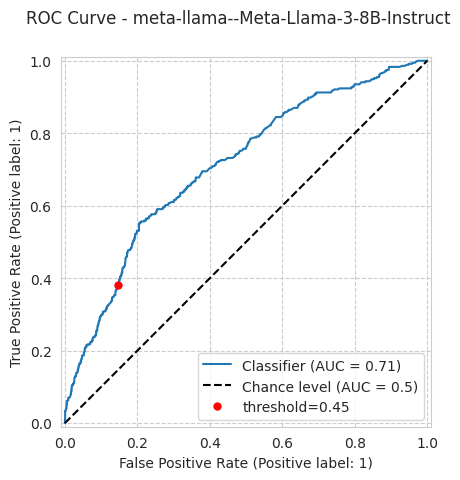
Meta-Llama-3-8B-Instructfollows the multiple-choice answer format and produces well-spread risk scores. The base model collapses to near-zero scores, which drives the true-positive rate (TPR / recall) close to zero regardless of threshold.Read the right metric and fit the threshold. On an imbalanced target the TPR stays modest, so compare models with the threshold-independent ROC AUC, and fit the decision threshold on a few training rows rather than assuming 0.5.
[13]:
%%time
# Fit the decision threshold on a few held-out training rows instead of
# assuming 0.5 (good practice on imbalanced targets like this one).
bench.run(results_root_dir=".", fit_threshold=100)
CPU times: user 3min 4s, sys: 1.44 s, total: 3min 6s
Wall time: 3min 5s
[13]:
{'threshold': np.float64(0.452562874251497),
'n_samples': 1963,
'n_positives': 354,
'n_negatives': 1609,
'model_name': 'meta-llama--Meta-Llama-3-8B-Instruct',
'accuracy': 0.7687213448802853,
'tpr': 0.3813559322033898,
'fnr': 0.6186440677966102,
'fpr': 0.14605344934742076,
'tnr': 0.8539465506525793,
'balanced_accuracy': 0.6176512414279846,
'precision': 0.36486486486486486,
'ppr': 0.18848700967906265,
'log_loss': 0.47507568589179683,
'brier_score_loss': 0.15090198061668986,
'ppr_ratio': 0.9796071889973671,
'ppr_diff': 0.0038833560666928224,
'tnr_ratio': 0.9936932801809975,
'tnr_diff': 0.005403413594926687,
'precision_ratio': 0.7697111631537862,
'precision_diff': 0.09482481517197039,
'balanced_accuracy_ratio': 0.9612301228041655,
'balanced_accuracy_diff': 0.024534608289319082,
'fpr_ratio': 0.9636458333333332,
'fpr_diff': 0.005403413594926687,
'accuracy_ratio': 0.9486453843603466,
'accuracy_diff': 0.040518320596423796,
'tpr_ratio': 0.8685143409603608,
'tpr_diff': 0.054472630173564796,
'fnr_ratio': 0.9149113660062566,
'fnr_diff': 0.05447263017356474,
'equalized_odds_ratio': 0.9149113660062566,
'equalized_odds_diff': 0.054472630173564796,
'roc_auc': 0.7102325197599659,
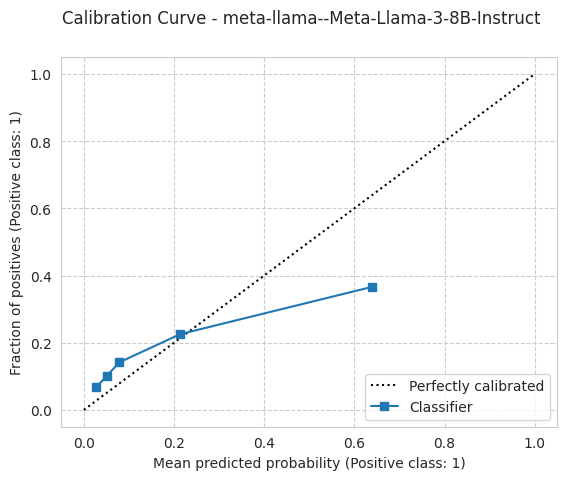
'ece': 0.08799361086494228,
'ece_quantile': 0.08777365300241867,
'threshold_fitted_on': 100,
'sensitive_attribute': 'SEX',
'predictions_path': '/lustre/home/acruz/folktexts/notebooks/meta-llama--Meta-Llama-3-8B-Instruct_bench-1697125874/health-care utilization_subsampled-0.1_seed-42_hash-3033721056.test_predictions.csv',
'config': {'numeric_risk_prompting': False,
'cot_prompting': False,
'enable_thinking': False,
'few_shot_config': None,
'use_chat_template': False,
'chat_prompt': 'default',
'system_prompt': 'default',
'batch_size': None,
'context_size': None,
'correct_order_bias': True,
'feature_subset': None,
'population_filter': None,
'seed': 42,
'prompt_variation': None,
'model_name': 'meta-llama--Meta-Llama-3-8B-Instruct',
'model_hash': 2381213563,
'task_name': 'health-care utilization',
'task_hash': 3969950215,
'dataset_name': 'health-care utilization_subsampled-0.1_seed-42_hash-3033721056',
'dataset_subsampling': 0.1,
'dataset_hash': 3033721056},
'benchmark_hash': 792125597,
'results_dir': '/lustre/home/acruz/folktexts/notebooks/meta-llama--Meta-Llama-3-8B-Instruct_bench-792125597',
'results_root_dir': '/lustre/home/acruz/folktexts/notebooks',
'current_time': '2026.06.09-20.58.30',
'plots': {'roc_curve_path': '/lustre/home/acruz/folktexts/notebooks/meta-llama--Meta-Llama-3-8B-Instruct_bench-792125597/imgs/roc_curve.pdf',
'calibration_curve_path': '/lustre/home/acruz/folktexts/notebooks/meta-llama--Meta-Llama-3-8B-Instruct_bench-792125597/imgs/calibration_curve.pdf',
'score_distribution_path': '/lustre/home/acruz/folktexts/notebooks/meta-llama--Meta-Llama-3-8B-Instruct_bench-792125597/imgs/score_distribution.pdf',
'score_distribution_per_label_path': '/lustre/home/acruz/folktexts/notebooks/meta-llama--Meta-Llama-3-8B-Instruct_bench-792125597/imgs/score_distribution_per_label.pdf',
'roc_curve_per_subgroup_path': '/lustre/home/acruz/folktexts/notebooks/meta-llama--Meta-Llama-3-8B-Instruct_bench-792125597/imgs/roc_curve_per_subgroup.pdf',
'calibration_curve_per_subgroup_path': '/lustre/home/acruz/folktexts/notebooks/meta-llama--Meta-Llama-3-8B-Instruct_bench-792125597/imgs/calibration_curve_per_subgroup.pdf'}}
[14]:
bench.plot_results();
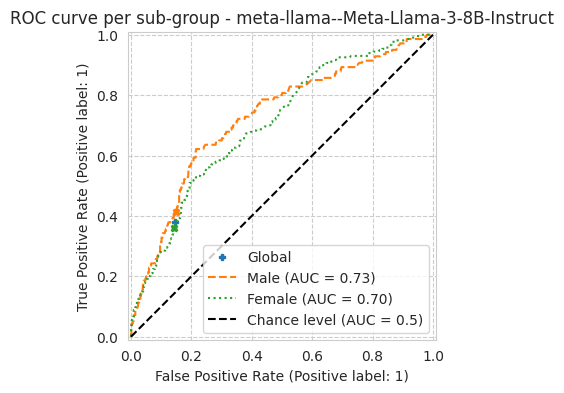
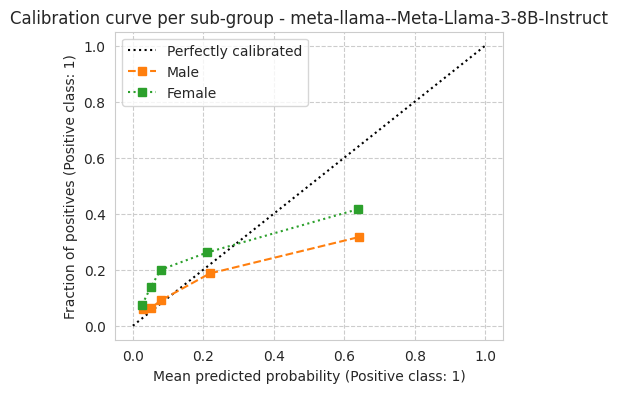
[15]:
bench.results
[15]:
{'threshold': np.float64(0.452562874251497),
'n_samples': 1963,
'n_positives': 354,
'n_negatives': 1609,
'model_name': 'meta-llama--Meta-Llama-3-8B-Instruct',
'accuracy': 0.7687213448802853,
'tpr': 0.3813559322033898,
'fnr': 0.6186440677966102,
'fpr': 0.14605344934742076,
'tnr': 0.8539465506525793,
'balanced_accuracy': 0.6176512414279846,
'precision': 0.36486486486486486,
'ppr': 0.18848700967906265,
'log_loss': 0.47507568589179683,
'brier_score_loss': 0.15090198061668986,
'ppr_ratio': 0.9796071889973671,
'ppr_diff': 0.0038833560666928224,
'tnr_ratio': 0.9936932801809975,
'tnr_diff': 0.005403413594926687,
'precision_ratio': 0.7697111631537862,
'precision_diff': 0.09482481517197039,
'balanced_accuracy_ratio': 0.9612301228041655,
'balanced_accuracy_diff': 0.024534608289319082,
'fpr_ratio': 0.9636458333333332,
'fpr_diff': 0.005403413594926687,
'accuracy_ratio': 0.9486453843603466,
'accuracy_diff': 0.040518320596423796,
'tpr_ratio': 0.8685143409603608,
'tpr_diff': 0.054472630173564796,
'fnr_ratio': 0.9149113660062566,
'fnr_diff': 0.05447263017356474,
'equalized_odds_ratio': 0.9149113660062566,
'equalized_odds_diff': 0.054472630173564796,
'roc_auc': 0.7102325197599659,
'ece': 0.08799361086494228,
'ece_quantile': 0.08777365300241867,
'threshold_fitted_on': 100,
'sensitive_attribute': 'SEX',
'predictions_path': '/lustre/home/acruz/folktexts/notebooks/meta-llama--Meta-Llama-3-8B-Instruct_bench-1697125874/health-care utilization_subsampled-0.1_seed-42_hash-3033721056.test_predictions.csv',
'config': {'numeric_risk_prompting': False,
'cot_prompting': False,
'enable_thinking': False,
'few_shot_config': None,
'use_chat_template': False,
'chat_prompt': 'default',
'system_prompt': 'default',
'batch_size': None,
'context_size': None,
'correct_order_bias': True,
'feature_subset': None,
'population_filter': None,
'seed': 42,
'prompt_variation': None,
'model_name': 'meta-llama--Meta-Llama-3-8B-Instruct',
'model_hash': 2381213563,
'task_name': 'health-care utilization',
'task_hash': 3969950215,
'dataset_name': 'health-care utilization_subsampled-0.1_seed-42_hash-3033721056',
'dataset_subsampling': 0.1,
'dataset_hash': 3033721056},
'benchmark_hash': 792125597,
'results_dir': '/lustre/home/acruz/folktexts/notebooks/meta-llama--Meta-Llama-3-8B-Instruct_bench-792125597',
'results_root_dir': '/lustre/home/acruz/folktexts/notebooks',
'current_time': '2026.06.09-20.58.30',
'plots': {'roc_curve_path': '/lustre/home/acruz/folktexts/notebooks/meta-llama--Meta-Llama-3-8B-Instruct_bench-792125597/imgs/roc_curve.pdf',
'calibration_curve_path': '/lustre/home/acruz/folktexts/notebooks/meta-llama--Meta-Llama-3-8B-Instruct_bench-792125597/imgs/calibration_curve.pdf',
'score_distribution_path': '/lustre/home/acruz/folktexts/notebooks/meta-llama--Meta-Llama-3-8B-Instruct_bench-792125597/imgs/score_distribution.pdf',
'score_distribution_per_label_path': '/lustre/home/acruz/folktexts/notebooks/meta-llama--Meta-Llama-3-8B-Instruct_bench-792125597/imgs/score_distribution_per_label.pdf',
'roc_curve_per_subgroup_path': '/lustre/home/acruz/folktexts/notebooks/meta-llama--Meta-Llama-3-8B-Instruct_bench-792125597/imgs/roc_curve_per_subgroup.pdf',
'calibration_curve_per_subgroup_path': '/lustre/home/acruz/folktexts/notebooks/meta-llama--Meta-Llama-3-8B-Instruct_bench-792125597/imgs/calibration_curve_per_subgroup.pdf'}}