Welcome to BenchBench’s documentation!¶

BenchBench is a Python package that provides a suite of tools to evaluate multi-task benchmarks focusing on task diversity and sensitivity to irrelevant changes.
Research shows that for all multi-task benchmarks there is a trade-off between task diversity and sensitivity. The more diverse a benchmark, the more sensitive its ranking is to irrelevant changes. Irrelevant changes are things like introducing weak models, or changing the metric in ways that shouldn’t matter.
Based on BenchBench, we’re maintaining a living benchmark of multi-task benchmarks. Visit the project page to see the results or contribute your own benchmark.
Please see our paper for all relevant background and scientific results. Cite as:
@inproceedings{zhang2024inherent,
title={Inherent Trade-Offs between Diversity and Stability in Multi-Task Benchmarks},
author={Guanhua Zhang and Moritz Hardt},
booktitle={International Conference on Machine Learning},
year={2024}
}
Quick Start¶
To install the package, simply run:
pip install benchbench
Example Usage¶
To evaluate a cardinal benchmark, you can use the following code:
from benchbench.data import load_cardinal_benchmark
from benchbench.measures.cardinal import get_diversity, get_sensitivity
data, cols = load_cardinal_benchmark('GLUE')
diversity = get_diversity(data, cols)
sensitivity = get_sensitivity(data, cols)
To evaluate an ordinal benchmark, you can use the following code:
from benchbench.data import load_ordinal_benchmark
from benchbench.measures.ordinal import get_diversity, get_sensitivity
data, cols = load_ordinal_benchmark('HELM-accuracy')
diversity = get_diversity(data, cols)
sensitivity = get_sensitivity(data, cols)
To use your own benchmark, you just need to provide a pandas DataFrame and a list of columns indicating the tasks. Check the documentation for more details.
Reproduce the results from our paper¶
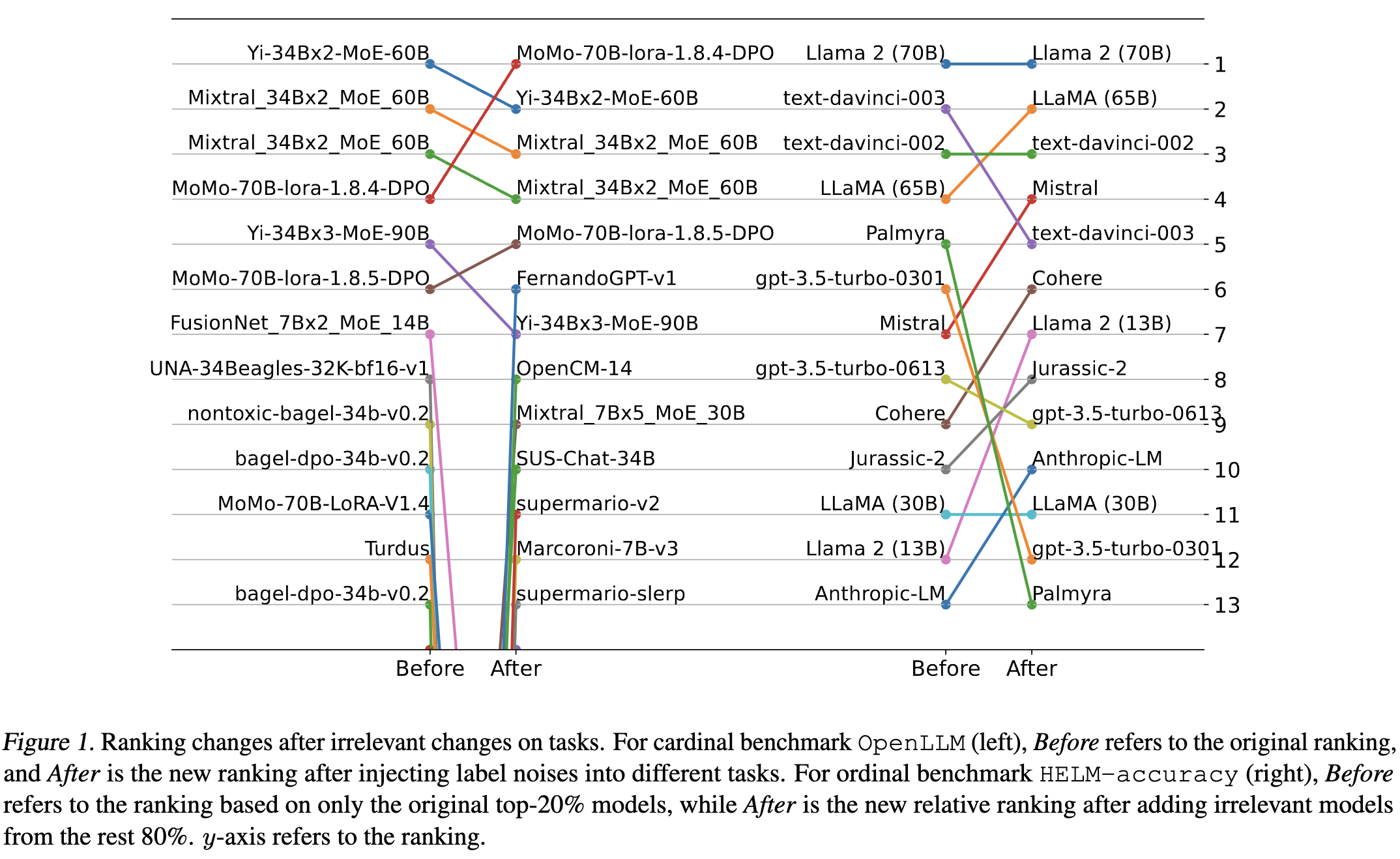
You can reproduce the figures from our paper using the following Colabs:
Contents: